Milestone 2 Process Book
Main Page Milestone 1Basic Info
- Title: Team Todd
- Russell Scharf, rscharf@wustl.edu
- Marissa Kalkar, mkalkar@wustl.edu
- Bo Anderson, boanderson@wustl.edu
- Repo link: https://github.com/csex57/cancer
Overview and Motivation
Cancer, a diverse class of diseases, is typically characterized by uncontrollable cell growth. This simplification is often misleading, as in reality the disease is extremely complex and is responsible for nearly a sixth of deaths worldwide (Bray). Roughly 1 in 2 men and 1 in 3 women will themselves develop cancer over the course of their lives, and it goes without saying that nearly everyone in the world will be touched by cancer in some capacity throughout their lifetime.
Despite its massive prevalence and enormous research effort, the age adjusted mortality* rate for cancer patients has remained stagnant since 1930 (Azra Raza). This means that in over 90 years, the life expectancy of cancer patients has remained largely unchanged. Despite frequent news of “breakthroughs in treatment” and “game changing discoveries”, the cancer treatment complex composed of clinicians, researchers, and pharmaceutical companies remains largely stumped in combatting and curing cancer. Massive amounts of funding and resources are allocated towards cancer research each year but the return on investment remains unfathomably low.
*age adjusted mortality: controls for the effects of differences in population age distributions
Related Work
Azra Raza is an oncologist and professor of medicine at Columbia University. Several of her works, including her book titled The First Cell, have inspired our team to pursue this project. While extremely optimistic about the future of the war against cancer, Raza is frusterated with how little progress has been made over the years.
The notion that progress is low is surprising given the amount of resources invested into cancer research and drug development each year. Our team wanted to visualize cancer diagnosis and mortality rates to observe whether or not Raza's frustration is justified.
Questions
Questions: What questions are you trying to answer? How did these questions evolve throughout the project? What new questions did you consider in the course of your analysis?
We are aiming to answer the following questions are answered for each type of cancer:
- Who is affected the most by the cancer in the US by state and demographic?
- What is the survival rate for type of cancer?
- What are the trends of cancer rates throughout the years?
- What stage is the type of cancer usually caught?
- What are the different treatment options for this type of cancer?
- What are the survival rates for each treatment option?
In addition, the prevailing race of diagnoses per year for each cancer type is white. That is, for cancer cases in each year, our data shows that the large majority of these people are white. This unbalance is again likely due to an imperfect process that medical organizations report that data to the government.
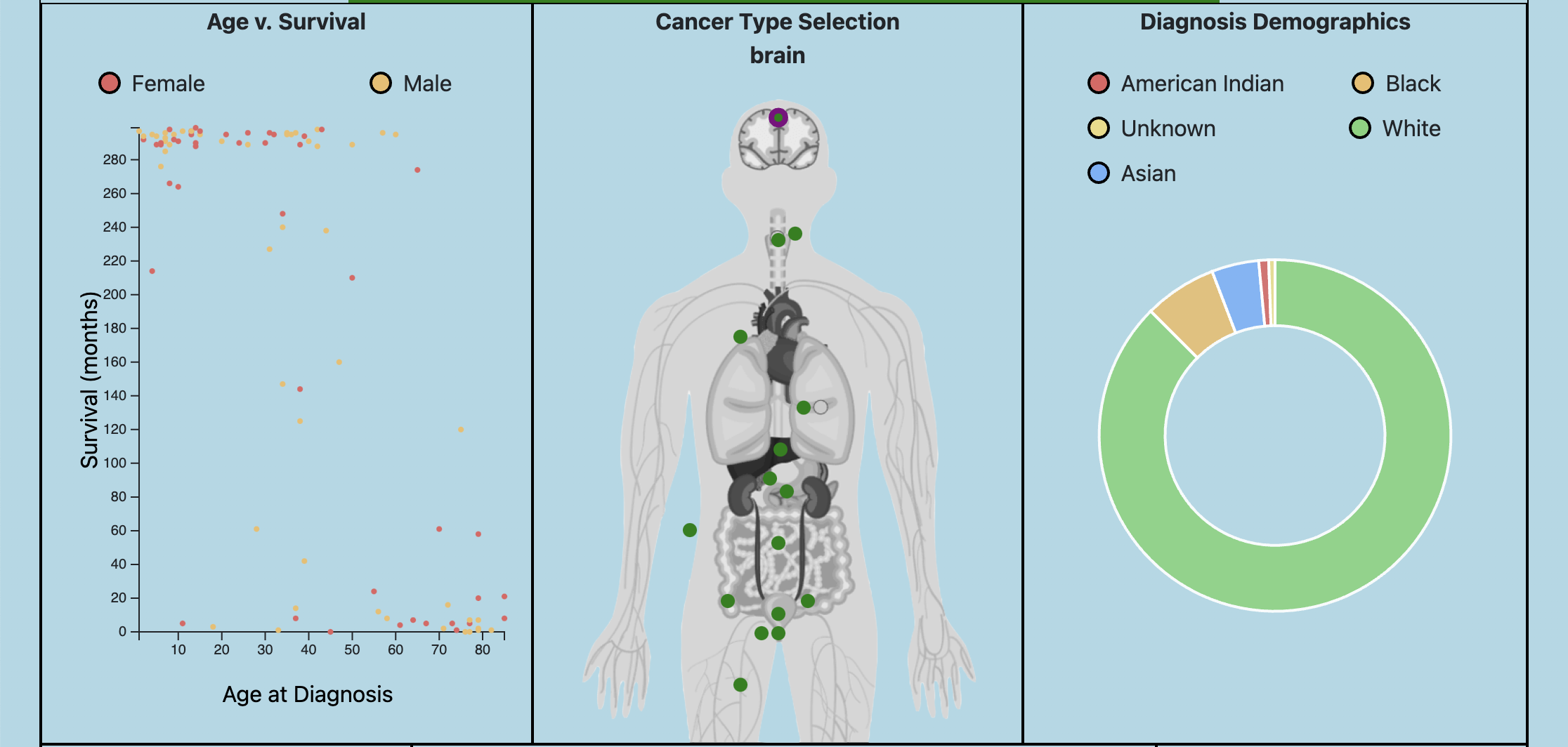
Over the course of analyzing the data, we thought it would be interesting to examine the correlation between the age of diagnosis and survival time of a patient. As a result, we created a scatter plot that contains a random subset of at most 100 cases from our data of over 5 million. We believe that this plot complements the other ones well, in that it is the only one where data from specific, stand-alone cases are depicted.
Data
Acquiring and parsing data has proven to be an extremely large part of making this project successful.The Centers for Disease Control and Prevention (CDC) have set up databases that “researchers can access and analyze high-quality population-based cancer incidence data on the entire United States population. De-identified cancer incidence data are available to researchers for free in public use databases.” (CDC). The data available to the public include cancer incidence and population data for all 50 states, the District of Columbia, and Puerto Rico, providing information on more than 31 million cancer cases.
The databases include data by demographic characteristics (for example, age, sex, and race) and tumor characteristics (for example, year of diagnosis, primary tumor site, histology, behavior, and stage at diagnosis) (United States Cancer Statistics). The current data comes from the 2020 National Program of Cancer Registries (NPCR) and Surveillance, Epidemiology, and End Results (SEER) program submissions, which include cancer cases diagnosed from January 1, 2001 through December 31, 2018. The data is accessible through the SEERStat software.
Our team has been approved to access the data and download the SEERStat software required to do so. The data we have downloaded thus far consists of over 5 million individual cases of cancer, each with over 200 variables that describe each case (age, race, cancer site, treatment, etc.). Many of the variables that we will be using need some adjusting from the raw data. For example, the type of cancer that each patient had is in the form of a code. A table online gives the conversion from each code to a specific cancer type. We used R to efficiently translate each code into its corresponding cancer type.
Feeding D3 a table of over 5 rows would be a flawed approach for what we are trying to achieve. This would lead to extremely slow runtimes and would ultimately get in the way of the information we are trying to convey to the users of our visualizations. To that end, we used R to do a lot of the computationally-intensive data processing. For example, our visualization allows for users to look at the proportion of new diagnoses that occurred in different racial groups for a cancer and year of their choice. To lighten the workload of JavaScript, almost all of the computation necessary to display this data is already done. The 5 million rows of individual cancer cases were condensed to a file that contains only the information needed to create the visualization itself.
Exploratory Data Analysis
It was important to get a sense of what our data looked like before deciding on which visualizations to pursue. The four plots below were helpful in deciding what made sense to pursue, and issues to be aware of.
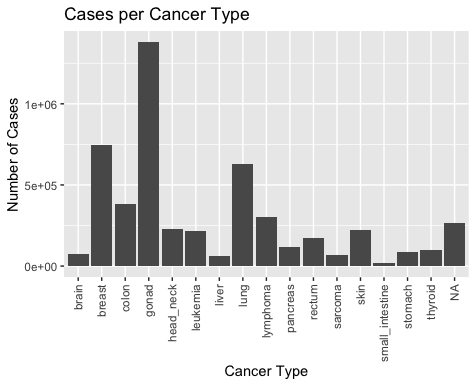
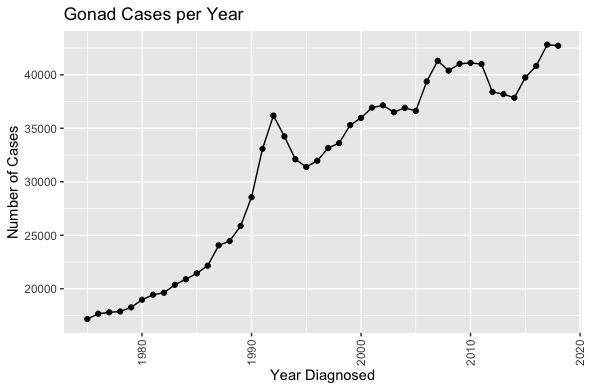
Specifically, it is important to note the large number of gonad cancer cases and relatively small number of small intestine cancer cases, as well as the rising number of diagnosed cases per year. While this would suggest that cancer cases are rising overall in the United States, there are other possible explanations to consider, such as improved reporting from doctors, or improved cancer detection techniques.
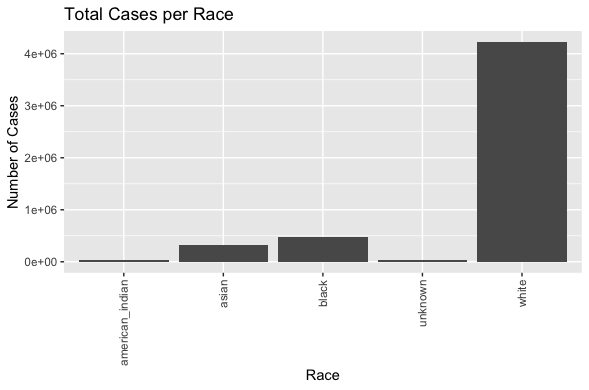
The plot in the bottom left shows that white people represent the majority of reported cancer cases. This too can be interpreted to mean many different things, but it is definitely interesting to note.
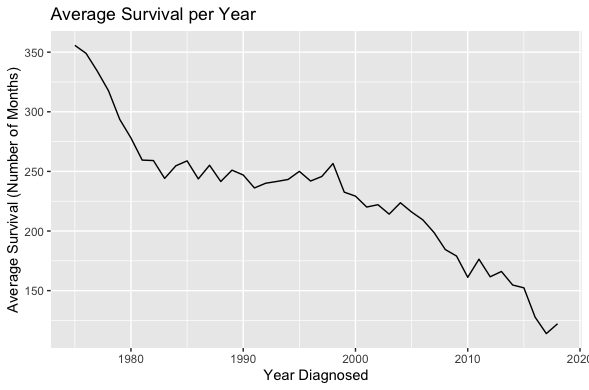
Lastly, the plot in the bottom right showing survival over time is the most surprising. It would have been more reassuring to see survival rates increasing over time, but we are actually seeing just the opposite.
Overall, these initial plots reassure our team of our goal and we believe the visualizations in the proposal will be valuable and informative.
Design Evolution
Design Evolution: What are the different visualizations you considered? Justify the design decisions you made using the perceptual and design principles you learned in the course. Did you deviate from your proposal?
Throughout the course of our preliminary research, it was our goal to create a centralized, informative webpage that holds a lot of information in one condensed, organized area.
In order to achieve this, we placed an interactive human body at the center to indicate the main navigation hub. The human body will cause all of its surroundings to change, providing
a visually-pleasing transition into the next cancer-type data set.
After the obtaining the data set as described earlier, we gained a better sense of the information we could use, leading us to want to provide a decent amount of information. The only way to achieve
this is to avoid repeating/common elements to display the data; the graphs should all be unique and eye-catching in their own way. Below is the original design made from PowerPoint slides:
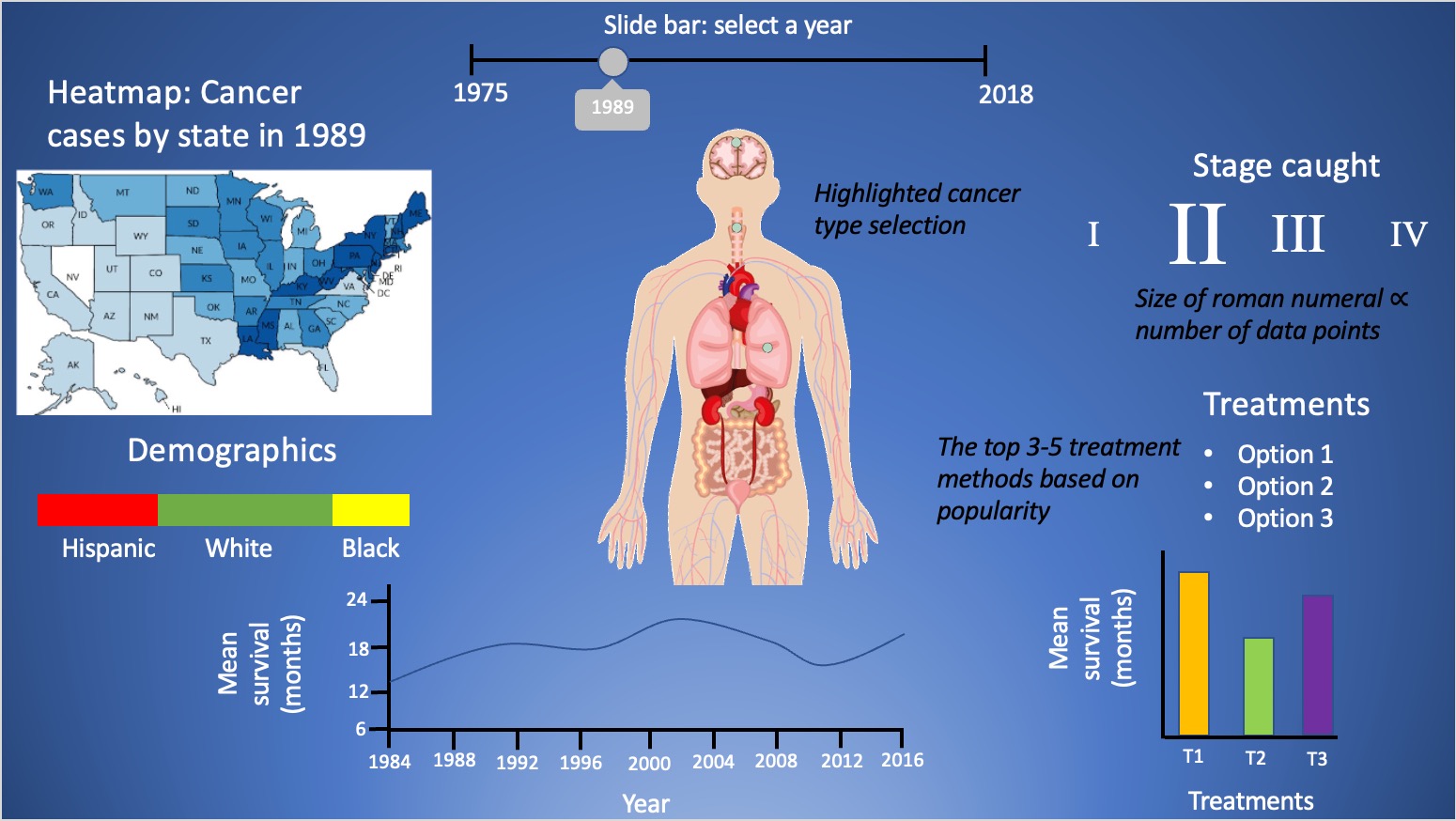
After turning in our project proposal, we stuck to our script closely as well as implementing them as sketched out, upon which we can clean-up certain areas later. As can be observed below with the current implementation, we have included many features introduced previously in this class including:
- D3 Event Handling
- jQuery
- SVG Charts
Our initial plan contained a plot that showed geographical information of where the cancer cases were coming from across the United States. Our team later realized that this plot would not be possible to create, since our data lacked any geographical information. This gave us the opportunity to choose different pieces of data that would convey useful information to the user. We decided to make a scatter plot showing the correlation between the age at diagnosis and survival time. Another unique feature of this plot is that there are no summary statistics being used to convey the data. Each dot on the plot is representative of a single patient.
Current Version of Webpage:
Implementation
- Slidebar - We felt it was very important to show cancer trends throughout the years. This can help patients or researchers understand how things have gotten better, and what to learn from previous trends.
- Scatterplot - For the selected year and cancer type, a random subset of these patients are chosen and their age and survival times are shown in this plot.
- Selected Organ - Selecting which type of cancer makes the visualization specific to what the user is interested in viewing. Looking through different pieces of data that have to do with each type allows the user to explore the trends of each. This, in combination with looking through various dates, allows the user to look at the data from multiple angles.
- Demographics - Pie Chart: We decided to implement a pie chart to display the demographics affected by each type of cancer. We felt that the pie chart easily displayed this info because the different demographics can represent a part of 100% of the cancer population.
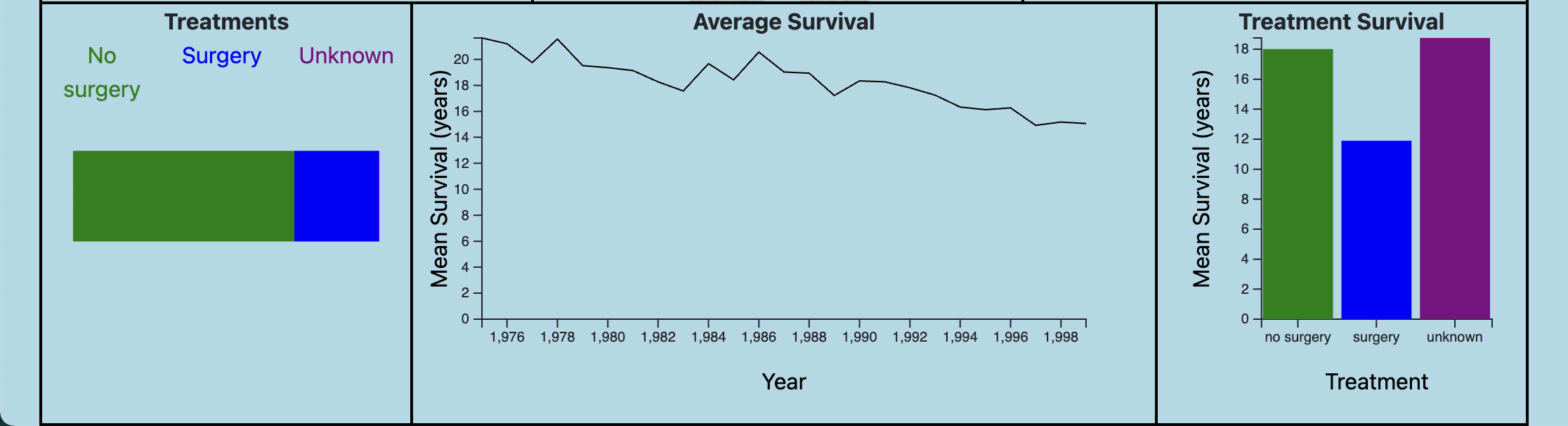
- Treatment - This chart helps viewers get a sense of how the selected cancer type is treated.
- Mean Survival - Line Chart: We felt that a line chart can clearly show the trends of survival rates throughout the years.
- Average Survival of each Treatment - Bar Chart: By viewing survival rates of each treatment, a cancer patient can form a decision based off of real data and outcomes.
Evaluation
We learned a lot about how cancer suvival rates, treatments, and demographics have changed over time. We had the data, but we didn't know these trends until putting the data into interactive visualizations. Our group has learned a lot about different cancer trends and room for improvement within the treatments of the different types of cancer.
Questions answered:
- Who is affected the most by the cancer in the US by state and demographic? For the most part, trends show that the white demographic is affected the most by cancer. We can see this clearly through the pie chart when clicking through the different types of cancer. To determine whether this is due to bias in the data, further studies should be conducted.
- What is the survival rate for type of cancer? Oddly, the line graph depicts that survival rates for almost all cancers have decreased over the years. Again, imperfect data might be causing this to be the case. Either way, visualizing the data is a great way to examine if there are flaws in it.
- What cancer types have low survival rates? High survival rates? The data shows that lung and pancreas cancer have among the lowest survival times, whereas skin and thyroid cancer have among the highest survival times.
- What are the different treatment options for this type of cancer? Our data supports 3 different types of treatments: no surgery, surgery, or some other from of treatment. The hope is that the user can do seperate research on other forms of treatment after understanding what survival rates are between the 3.
- What are the survival rates for each treatment option? Survival rates vary by type of cancer, which is shown in our visualization. Each of these rates can be viewed in the bar graph.
Overall, the main aspect that needs to be improved is the aesthetic of the visualization. We should work on improving the color scheme and making the visualizations appear more modern looking. User testing will help us find additional improvements that we can make.
Link to Youtube Screencast is in README.md file